In diesem Blogbeitrag geben wir eine Outline unserer Lösung zur automatisierten Transaktionsverarbeitung mit einem Machine Learning (ML) Modell.
Szenario
Bei einem Kunden gehen täglich viele Spenden ein, die im IT-System registriert und prozessiert werden müssen. Letzteres besteht aus einem CRM-System und weiteren Komponenten.
Für die Verarbeitung der Spende ist die Identifikation der Adresse, des Spendenzwecks sowie der Spendenanlass nötig. Die Angaben der Spender:innen beim Überweisungszweck erschweren eine logikbasierte Verarbeitung, da das Eingabefeld keiner festen Struktur folgt: Sowohl auf einer Papier-Überweisung als auch in elektronischer Form ist weder eine absehbare Reihenfolge noch die Vollständigkeit der Angaben gegeben. Die folgenden erfundenen Beispiele zum Überweisungszweck verdeutlichen diese Problematik:
- 22175 Boxhagener Str., Anna Kortig, Spende für Kinder in Not
- S Ackermann Herrmanstrasse 65 Bechtheim. 40. Geburtstag, keine Quittung
- Patrick Wurfel. 58802 Knesebeckstraße 37. Spende Afrika
Der bis zu 200 Zeichen lange Text kann zudem Schreib-/Tippfehler enthalten.
Einbezug des Machine Learnings
Um die Performance der automatischen Verarbeitung zu erhöhen, wurde der Einsatz von Machine Learning erprobt.
Während des Entwicklungsprozesses wurde zunächst der Datenfluss analysiert, um im Anschluss Anhaltspunkte zu erhalten, wie die Datenqualität im System erhöht werden konnte, damit eine möglichst hochwertige Daten-Ausgangslage hinsichtlich der Trainingsdaten gegeben war.
Der zur Entwicklung gewählte technische Ansatz basiert auf einem ML-Webservice (Python), der den übermittelten Text analysiert und die extrahierten Informationen zurückgibt. Die aus dem Machine Learning gewonnene Informationen werden mittels C#-Code an das CRM-System übergeben, woraufhin ein Abgleich der durch ML aufgewerteten Daten mit den Daten des CRM-Systems stattfinden kann. Bei einem erfolgreichen Abgleich wird die gesamte Transaktion im System verbucht. Sollte kein Match gefunden werden oder für den Fall, dass die Transaktion andere Fehler aufweist, wird der Datensatz zur manuellen Weiterverarbeitung aussortiert, da bei einer fehlerhaften Verbuchung erneut Aufwand anfallen würde.
In Zusammenarbeit mit dem Kunden wurden im Entwicklungsprozess zunächst semantische Einheiten (Kategorien) erarbeitet, die im Überweisungszweck repräsentiert sein können. Anschließend wurden Methoden erdacht und getestet, um diese semantischen Einheiten im CRM abzuleiten. Dadurch eröffnet sich die Möglichkeit, Parameter zur Kontrolle der semantischen Einheiten im System einzuführen.



Mit diesem Konzept wurde mit der Implementierung des ML-Models begonnen. Als ML-Plattform wurde eine Python-Library für das Natural Language Processing gewählt, da dieses Framework genügend Flexibilität bezüglich der Konfiguration der Entwicklungspipeline bietet.
- Auswahl von Trainings-Datensätzen mit hinreichender Komplexität und Diversität der Daten
- Manuelle Annotation und Vorbereitung dieser Datensätze
- Training des ML-Models für das Transaction Processing
- Evaluierung der Model Performance
- Iteration des Datensatzes oder dessen Struktur
- Auswertung des Outputs
Ergebnis
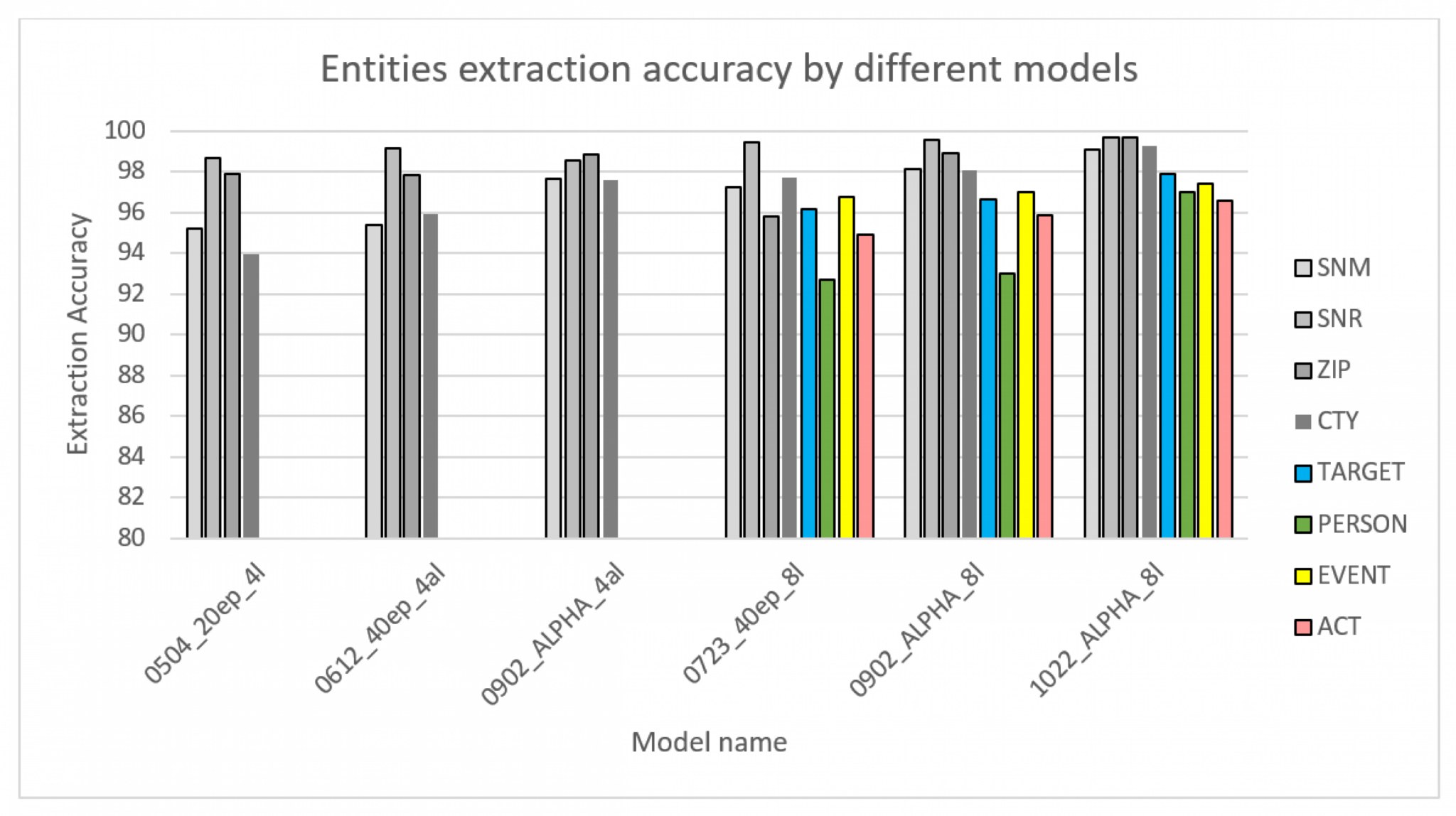
Während wir die anfänglichen Modelle mit lediglich bis zu 4 semantischen Einheiten trainiert haben, wurde die Komplexität kontinuierlich gesteigert, sodass abschließend alle semantischen Einheiten erfolgreich vom ML-Model erkannt wurden. Hierdurch konnte insgesamt die Effizienz der von zu Beginn 70% Genauigkeit auf mitunter bis hin zu über 95% Genauigkeit gesteigert werden. Die Auswertung je semantischer Einheit ermöglichte ein Fine-Tuning der Modelle, mit dem die Genauigkeit für eine bestimmte semantische Einheit gezielt gesteigert werden konnte, ohne dabei unbewusst die Genauigkeit einer anderen Einheit zu kompromittieren.
Machine Learning Discovery
Durch zunehmende Datenmengen und Fortschritte im Bereich Machine Learning lohnt sich dessen Einsatz in immer mehr Bereichen. Anwendungsfälle und Szenarien sollten jedoch vorab hinreichend auf Umsetzbarkeit und Kosten-Nutzen hin analysiert werden. Wir bieten sowohl Konzeption und Beratung an und freuen uns über Ihre Anfrage!